|
Ремонт и upgrade компьютеров своими рукамиСПОСОБЫ КОДИРОВАНИЯ ДАННЫХ |
||||||||||||||||||||||||
 |
|||||||||||||||||||||||||
| Если у вас появятся вопросы, не освещенные на нашем сайте, вы можете задать вопрос непосредственно нашим специалистам по электронной почте: upgradecomputer@yandex.ru
|
Данные на магнитном носителе хранятся в аналоговой форме. В то же время сами данные представлены в цифровом виде, так как являются последовательностью нулей и единиц. При выполнении записи цифровая информация, поступая на магнитную головку, создает на диске магнитные домены соответствующей полярности. Если во время записи на головку поступает положительный сигнал, магнитные домены поляризуются в одном направлении, а если отрицательный — в противоположном. Когда меняется полярность записываемого сигнала, происходит также изменение полярности магнитных доменов. Если во время воспроизведения головка регистрирует группу магнитных доменов одинаковой полярности, она не генерирует никаких сигналов; генерация происходит только тогда, когда головка обнаруживает изменение полярности. Эти моменты изменения полярности называются сменой знака. Каждая смена знака приводит к тому, что считывающая головка выдает импульс напряжения; именно эти импульсы устройство регистрирует во время чтения данных. Но при этом считывающая головка генерирует не совсем тот сигнал, который был записан; на самом деле она создает ряд импульсов, каждый из которых соответствует моменту смены знака. Чтобы оптимальным образом расположить импульсы в сигнале записи, необработанные исходные данные прозапускаются через специальное устройство, то называется кодером/декодером {encoder/decoder). Это устройство преобразует двоичные данные в электрические сигналы, оптимизированные в контексте размещения зон смены знака на дорожке записи. Во время считывания кодер/декодер выполняет обратное преобразование: восстанавливает из сигнала последовательность двоичных данных. За прошедшие годы было разработано несколько методов кодирования данных, причем главной целью разработчиков было достижение максимальной эффективности и надежности записи и считывания информации. При работе с цифровыми данными особое значение приобретает синхронизация. Во время считывания или записи очень важно точно определить момент каждой смены знака. Если синхронизация отсутствует, то момент смены знака может быть определен неправильно, в результате чего неизбежна потеря или искажение информации. Чтобы предотвратить это, работа передающего и принимающего устройств должна быть строго синхронизирована. Существует два пути решения данной проблемы. Во-первых, синхронизировать работу двух устройств, передавая специальный сигнал синхронизации (или синхросигнал) по отдельному каналу связи. Во-вторых, объединить синхросигнал с сигналом данных и передать их вместе по одному каналу. Именно в этом и заключается суть большинства способов кодирования данных. Если данные и синхросигнал передаются по одному каналу, то можно осуществить их взаимную временную привязку при передаче между любыми двумя устройствами. Простейший способ сделать это — перед передачей ячейки данных послать синхронизирующий сигнал. Применительно к магнитным носителям это означает, что, к примеру, ячейка, содержащая один бит информации, должна начинаться с зоны смены знака, которая выполняет роль заголовка. Затем рекомендуется (или не рекомендуется) переход, в зависимости от значения бита данных. Заканчивается рассматриваемая ячейка еще одной зоной смены знака, которая одновременно является стартовой для следующей ячейки. Преимущество этого метода состоит в том, что синхронизация не нарушается даже при воспроизведении длинных цепочек нулей (или единиц), а недостаток — в том, что дополнительные зоны смены знака, важные только для синхронизации, занимают место на диске, то могло бы использоваться для записи данных. Поскольку количество зон смены знака, которые можно записать на диске, ограничено возможностями технологий производства носителей и головок, при разработке дисковых накопителей изобретаются такие способы кодирования данных, с помощью которых можно было бы «втиснуть» как можно больше битов данных в минимальное количество зон смены знака. При этом приходится учитывать то неизбежное обстоятельство, что часть из них все равно будет использоваться только для синхронизации. Хотя разработано великое множество разнообразных методов, сегодня реально используются только три из них: ■ частотная модуляция (FM); ■ модифицированная частотная модуляция (MFM); ■ кодирование с ограничением длины поля записи (RLL). Далее эти методы рассматриваются на примере ASCII-кода символа «X».Частотная модуляция (FM) Метод кодирования FM {Frequency Modulation — частотная модуляция) был разработан прежде других и использовался при записи на гибкие диски так называемой одинарной плотности {single density) в первых ПК. Емкость таких односторонних дискет составляла всего 80 Кбайт. В 1970-х годах запись по методу частотной модуляции использовалась во многих устройствах, но сейчас от него полностью отказались. Модифицированная частотная модуляция (MFM) Основной целью разработчиков метода MFM {Modified Frequency Modulation — модифицированная частотная модуляция) было сокращение количества зон смены знака для записи того же объема данных по сравнению с FM-кодированием и соответственно увеличение потенциальной емкости носителя. При этом способе записи количество зон смены знака, используемых только для синхронизации, сокращается. Синхронизирующие переходы записываются только в начало ячеек с нулевым битом данных и только в том случае, если ему предшествует нулевой бит. Во всех остальных случаях синхронизирующая зона смены знака не формируется. Благодаря такому уменьшению количества зон смены знака при той же допустимой плотности их размещения на диске информационная емкость по сравнению с записью по методу FM удваивается. Вот почему диски, записанные по методу MFM, часто называют дисками двойной плотности {double density). Поскольку при рассматриваемом способе записи на одно и то же количество зон смены знака приходится вдвое больше «полезных» данных, чем при FM-кодировании, скорость считывания и записи информации на носитель также удваивается. При записи и воспроизведении данных по методу MFM требования, предъявляемые к точности синхронизации, более жесткие, чем при FM-кодировании. Однако все сложности были успешно преодолены, и MFM стал самым популярным методом кодирования на долгие годы. В табл. 9.1 приведено соответствие между битами данных и зонами смены знака. Таблица 9.1. Последовательность зон смены знака при записи по методу MFM
Кодирование с ограничением длины поля записи (RLL) Сегодня наиболее популярен метод кодирования с ограничением длины поля записи {Run Length Limited — RLL). Он позволяет разместить на диске в полтора раза больше информации, чем при записи по методу MFM, и в три раза больше, чем при FM-коди-ровании. При использовании этого метода происходит кодирование не отдельных битов, а целых групп, в результате чего создаются определенные последовательности зон смены знака. Метод RLL был разработан IBM и сначала использовался в дисковых накопителях больших машин. В конце 1980-х годов его стали использовать в накопителях на жестких дисках ПК, а сегодня он применяется почти во всех ПК. Как уже отмечалось, при записи по методу RLL одновременно кодируются целые подгруппы битов. Термин Run Length Limited (с ограничением длины пробега) составлен из названий двух основных параметров, которыми являются минимальное (длина пробега) и максимальное (предел пробега) число ячеек перехода, которые можно расположить между двумя зонами смены знака. Изменяя эти параметры, можно получать различные методы кодирования, но на практике используются только два из них: RLL 2,7 и RLL 1,7. Методы FM и MFM, в сущности, являются частными вариантами RLL. Так, к примеру, FM-кодирование можно было бы назвать RLL 0,1, поскольку между двумя зонами смены знака может располагаться максимум одна и минимум нуль ячеек перехода. Соответственно метод MFM в этой терминологии можно было бы обозначить RLL 1,3, так как в этом случае между двумя зонами смены знака может располагаться от одной до трех ячеек перехода. Однако при упоминании этих методов обычно используются более привычные названия FM и MFM. До последнего времени самым популярным был метод RLL 2,7, поскольку он позволял достичь высокой плотности записи данных (в 1,5 раза больше по сравнению с методом MFM) и достоверности (надежности) их воспроизведения. При этом соотношение размеров зон смены знака и участков с постоянной намагниченностью оставалось тем же, что и при методе MFM. Однако для накопителей очень большой емкости метод RLL 2,7 оказался недостаточно надежным. В большинстве современных жестких дисков высокой емкости используется метод RLL 1,7, который позволяет увеличить плотность записи в 1,27 раза по сравнению с MFM при оптимальном соотношении между величиными зон смены знака и участков с постоянной намагниченностью. За счет нетого снижения плотности записи (по сравнению с RLL 2,7) удалось существенно повысить надежность считывания данных. Это особенно важно, поскольку в накопителях большой емкости носители и головки уже приближаются к пределу возможностей современной технологии. И так как при разработке современных жестких дисков приоритет принадлежит надеж — ности считывания данных, можно ожидать, что в ближайшем будущем метод RLL 1,7 достигнет наибольшего распространения. Еще один редко используемый вариант RLL — метод RLL 3,9. Иногда его называют усовершенствованным RLL или ARRL {Advanced RLL). С его помощью можно достичь еще большей плотности записи информации, чем при использовании метода RLL 2,7. Но, к сожалению, надежность ARRL-кодирования очень невысока; его пытались использовать в некоторых контроллерах, но их выпуск был вскоре прекращен. Понять сущность RLL-кодирования без наглядных примеров довольно сложно, поэтому рассмотрим метод RLL 2,7, так как именно он чаще всего используется. Даже для этого конкретного варианта можно построить множество (тысячи!) таблиц перекодировки различных последовательностей битов в серии зон смены знака. Остановимся на таблице, которая использовалась IBM при создании кодеров/декодеров. Согласно этой таблице подгруппы данных длиной 2, 3 и 4 бит преобразуются в серии зон смены знака длиной 4, 6 и 8 битовых ячеек соответственно. При этом кодирование последовательностей битов происходит так, чтобы расстояние между зонами смены знаков было не слишком маленьким, но и не очень крупным. Первое ограничение вызвано тем, что величины разрешений головки и магнитного носителя, как правило, являются фиксированными. Второе ограничение необходимо для того, чтобы обеспечить синхронизацию устройств. В табл. 9.2 приведена схема кодирования по методу RLL 2,7, разработанная IBM. Таблица 9.2. Последовательность зон смены знака при записи по методу RLL 2,7
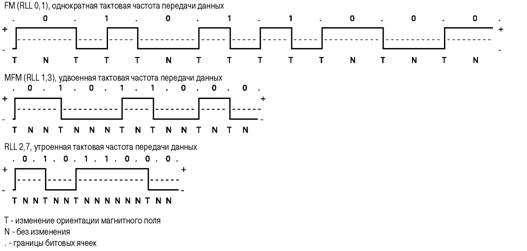 Рис. 9.8. Сигналы, формируемые во время записи ASCII-кода
символа «X» при способах кодирования FM, MFM и RLL 2,7
Рис. 9.8. Сигналы, формируемые во время записи ASCII-кода
символа «X» при способах кодирования FM, MFM и RLL 2,7
Сравнение способов кодирования На рис. 9.8 отображены диаграммы сигналов, формируемых при записи на жесткий диск ASCII-кода символа «X» для трех различных способов кодирования. В верхней строке каждой из этих диаграмм отображены отдельные биты данных (01011000) в битовых ячейках, границами которых являются синхронизирующие сигналы, обозначенные точками. Под этой строкой изображен сам сигнал, представляющий собой чередование положительных и отрицательных значений напряжения, причем в моменты смены полярности напряжения происходит запись зоны смены знака. В нижней строке отображены ячейки перехода, причем Т обозначает ячейку, содержащую зону смены знака, а N — ячейку, в той зоны смены знака нет. Разобраться в FM-кодировании очень просто. В каждой битовой ячейке содержится две ячейки перехода: одна для синхронизирующего сигнала, другая для самих данных. Все ячейки перехода, в которых записаны сигналы синхронизации, содержат зоны смены знака. В то же время ячейки перехода, в которых записаны данные, содержат зону смены знака только в том случае, если значение бита равно логической единице. При нулевом значении бита зона смены знака не формируется. Поскольку в нашем примере значение первого бита — 0, он будет записан в виде комбинации TN. Значение следующего бита равно 1, и ему соответствует комбинация ТТ. Третий бит — тоже нулевой (TN) и т. д. С помощью приведенной выше диаграммы FM-кодирования легко проследить всю кодирующую комбинацию для рассматриваемого примера байта данных. Отметим, что при данном способе записи зоны смены знака могут следовать непосредственно одна за другой; в терминах RLL-кодирования это означает, что минимальный «пробег» равен нулю. С другой стороны, максимально возможное количество пропущенных подряд зон смены знака не может превышать единицы — вот почему FM-кодирование можно обозначить как RLL 0,1. При MFM-кодировании в ячейках также записывается синхросигнал и биты данных. Но, как видно из схемы, ячейки для записи синхросигнала содержат зону смены знака только в том случае, если значения и текущего и предыдущего битов равны нулю. Первый бит слева — нулевой, значение же предыдущего бита в данном случае неизвестно, поэтому предположим, что он тоже равен нулю. При этом последовательность зон смены знака будет выглядеть как TN. Значение следующего бита равно единице, той всегда соответствует комбинация NT. Следующему нулевому биту предшествует единичный, поэтому ему соответствует последовательность NN. Аналогичным образом можно проследить процесс формирования сигнала записи до конца байта. Легко заметить, что минимальное и максимальное число ячеек перехода между любыми двумя зонами смены знака равно 1 и 3 соответственно. Следовательно, MFM-кодирование в терминах RLL может быть названо методом RLL 1,3. Поскольку в данном случае используется только половина зон смены знака (по сравнению с FM-кодированием), частоту синхронизирующего сигнала можно удвоить, сохранив при этом то же расстояние между зонами смены знака, то использовалось при методе FM. Это означает, что плотность записываемых данных остается такой же, как при FM-кодировании, но данных кодируется вдвое больше. Труднее всего разобраться в диаграмме, иллюстрирующей метод RLL 2,7, поскольку в нем кодируются не отдельные биты, а их подгруппы. Первая группа слева, совпадающая с одной из приведенных в табл. 9.2 комбинаций, состоит из трех битов: 010. Она преобразуется в такую последовательность зон смены знака: TNNTNN. Следующим двум битам (11) соответствует комбинация TNNN, а последним трем (000) — NNNTNN. Как видите, в данном примере для корректного завершения записи дополнительные биты не потребовались. Обратите внимание, что в этом примере минимальное и максимальное число пустых ячеек перехода между двумя зонами смены знака равно 2 и 6 соответственно, хотя в другом примере максимальное количество пустых ячеек перехода может равняться 7. Именно поэтому такой способ кодирования называется RLL 2,7. Поскольку в данном случае записывается еще меньше зон смены знака, чем при MFM-кодировании, частоту сигнала синхронизации можно увеличить в 3 раза по сравнению с методом FM и в 1,5 раза по сравнению с методом MFM. Это позволяет на таком же пространстве диска записать больше данных. Но необходимо отметить, что минимальное и максимальное физическое расстояние на поверхности диска между любыми двумя зонами смены знака одинаково для всех трех упомянутых методов кодирования. Декодеры PRML В последнее время в накопителях вместо традиционных усилителей считывания с пиковыми детекторами стала использоваться так называемая технология PRML {Partial-Response, Maximum-Likelihood — частичное определение, максимальное правдоподобие). Это позволяет повысить плотность расположения зон смены знака на диске в среднем на 40% и на столько же увеличить емкость носителя. Увеличение плотности записи приводит к тому, что пиковые значения напряжения при считывании данных могут накладываться друг на друга. При использовании метода PRML контроллер анализирует поток данных с головки посредством фильтрации, обработки и алгоритма определения (элемент частичного определения), а затем предсказывает последовательность битов, которые этот поток данных наилучшим образом представляет (элемент максимального правдоподобия). Обработка данных осуществляется цифровыми методами. В настоящее время в самых новых накопителях на жестких дисках с успехом используется описанная схема PRML. .
Вся информация собрана из открытых источников. При испльзовании материалов, размещайте ссылку на источник. |